“Language is the most massive and inclusive art we know, a mountainous and anonymous work of unconscious generations.” — Edward Sapir
If you merge language and technology in today’s context, your response would effortlessly emerge in just a second – ChatGPT.
ChatGPT has ushered in a revolutionary era of AI, transforming, and reshaping the entire world. It has encouraged us to consider the potential of LLM and its significant impact on Natural Language Processing (NLP).
Large language models (LLMs) like GPT-4 have shown impressive abilities in generating human-like text. However, they still face challenges when it comes to the retention of factual knowledge.
Exploring Challenges: LLMs and the Struggle with Factual Knowledge Retention
Large Language Models (LLMs), such as GPT-4, offer impressive linguistic abilities, yet they encounter notable challenges in retaining factual knowledge. While adept at generating human-like text, these models struggle with accurately preserving and recalling factual details.
A key challenge arises because LLMs prioritize language patterns and context more than exact factual accuracy. This preference can lead to inaccuracies in retaining and recalling specific details, making them susceptible to errors in factual knowledge.
Moreover, LLMs face the ongoing challenge of staying updated with the ever-evolving information landscape. The dynamic nature of facts poses a constant hurdle, requiring continuous adaptation and refinement of these models to align with the latest information.
To tackle these challenges, researchers and developers are carefully balancing the sophistication of language and the accuracy of facts in LLMs. They’re actively working to improve LLMs’ ability to remember and recall facts correctly. As progress continues, finding solutions to these challenges paves the way for the ongoing evolution of large language models.
Enhancing Factual Precision in Large Language Models
This is where retrieval-augmented generation (RAG) comes in combining the generative capabilities of LLMs with external knowledge sources. RAG has emerged as a promising technique for improving the factual grounding of LLMs while retaining their fluency.
Let’s learn this in detail.
What is Retrieval-Augmented Generation (RAG)?
Retrieval-augmented generation combines large language models with retrieval mechanisms to provide relevant knowledge to the LLM during text generation.
Retrieval-augmented generation refers to a hybrid approach in natural language processing where a model combines generative capabilities with the ability to retrieve relevant information from external sources.
Instead of relying solely on the model’s pre-existing knowledge, it dynamically pulls in information from external databases, documents, or other sources during the generation process. This approach aims to enhance the accuracy, relevance, and diversity of the generated content by leveraging both the model’s generative skills and the wealth of information available in external repositories.
Good Read: All About the Latest Technology Stint – Generative AI
The Fusion of Retrieval-Based Methods and Generative Models
RAG is fundamentally a hybrid model that seamlessly integrates two critical components.
- Retrieval-based methods involve accessing and extracting information from external knowledge sources such as databases, articles, or websites.
- Conversely, generative models excel in generating coherent and contextually relevant text.
What distinguishes RAG is its ability to harmonize these two components, creating a symbiotic relationship that allows it to comprehend user queries deeply and produce responses that are not just accurate but also contextually rich.
Pipeline:
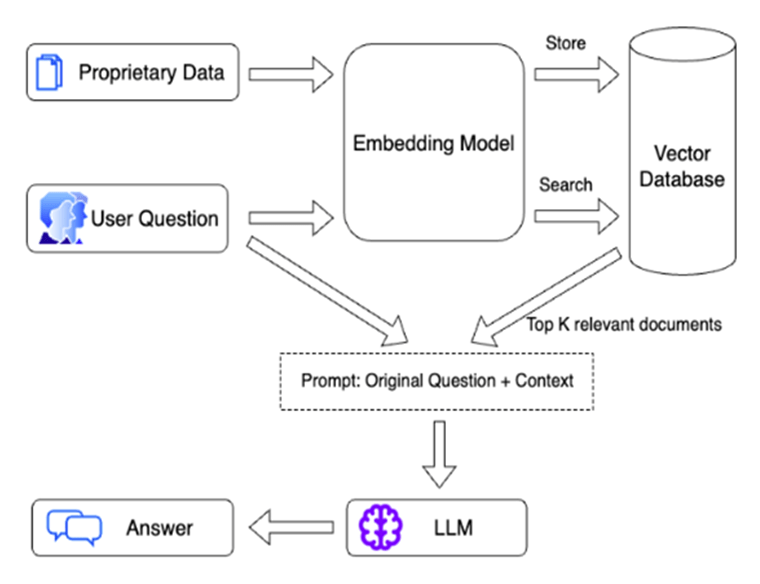
Now, let’s explore the different components within the fusion of Retrieval and Generative models methodology.
- Text Splitter: Splits documents to accommodate context windows of LLMs.
- Embedding Model: The deep learning model used to get embeddings of documents.
- Vector Stores: The databases where document embeddings are stored and queried along with their metadata.
- LLM: The Large Language Model responsible for generating answers from queries.
- Utility Functions: This involves additional utility functions such as Webretriver and document parsers that aid in retrieving and pre-processing files.
How Does It Work?
Retrieval Phase:
- Retrieval Component: The process begins with a retrieval component, often based on techniques like TF-IDF, BM25, or dense vector retrieval. This component searches a large dataset (such as a collection of documents or passages) to find the most relevant information related to the input query or context.
- Retrieved Information: The retrieval component returns a set of passages or documents that are deemed relevant to the input. These serve as the context for the generative model.
Generative Phase:
- Generative Model: The retrieved information is then passed to a generative model, typically a pre-trained language model like GPT (Generative Pre-trained Transformer). This model can generate human-like text based on the input it receives.
- Attention Mechanism: The generative model often employs an attention mechanism. This mechanism allows the model to focus more on certain parts of the retrieved information, enabling it to generate contextually relevant responses.
Output:
Generated Response: The final output of the RAG model is a generated response or content that combines information from the retrieval phase with the creative generation abilities of the language model. This response is intended to be contextually relevant and coherent.
Training:
Fine-tuning: The model may be fine-tuned on specific tasks or domains to improve its performance on a particular type of data.
Now, let’s see some of the benefits of this RAG approach.
What are the Benefits of Retrieval Augmented Generation (RAG)?
- Enhanced LLM Memory
RAG addresses the information capacity limitation of traditional Language Models (LLMs). Traditional LLMs have a limited memory called “Parametric memory.” RAG introduces a “Non-Parametric memory” by tapping into external knowledge sources. This significantly expands the knowledge base of LLMs, enabling them to provide more comprehensive and accurate responses.
- Improved Contextualization
RAG enhances the contextual understanding of LLMs by retrieving and integrating relevant contextual documents. This empowers the model to generate responses that align seamlessly with the specific context of the user’s input, resulting in accurate and contextually appropriate outputs.
- Updatable Memory
A standout advantage of RAG is its ability to accommodate real-time updates and fresh sources without extensive model retraining. This keeps the external knowledge base current and ensures that LLM-generated responses are always based on the latest and most relevant information.
Diverse Applications of Retrieval Augmented Generation (RAG)
Explore how Retrieval-Augmented Generation (RAG) transforms various domains, from enhancing chatbot interactions to revolutionizing legal research and healthcare.
- Chatbots and AI Assistants:
RAG enhances chatbots and AI assistants by infusing them with the ability to provide more contextually relevant and informative responses, improving user interactions.
- Education Tools:
In education, RAG proves helpful by assisting in content creation, generating educational materials, and offering contextual information to enhance learning experiences.
- Legal Research and Document Review:
RAG streamlines legal research and document review processes by swiftly retrieving and generating relevant legal information, aiding lawyers in their work.
- Medical Diagnosis and Healthcare:
In the medical field, RAG contributes to accurate diagnosis and healthcare by incorporating vast medical knowledge to assist professionals in decision-making processes.
- Language Translation with Context:
RAG revolutionizes language translation by providing contextually nuanced translations to improve the accuracy and naturalness of translated content.
RAG Shapes Tomorrow’s Language Models
The dynamic synergy of generative capabilities and information retrieval opens new avenues across diverse applications, from refining chatbot interactions to revolutionizing legal research, education, healthcare, and language translation.
As we witness the evolution of RAG, its potential to bridge the gap between generative models and real-world information continues to unfold. It promises a future where language models not only understand the context but actively contribute to knowledge enrichment and application in various fields.
The journey of RAG exemplifies the continuous innovation in natural language processing, offering a glimpse into the boundless possibilities that lie ahead.